Note: The description on this page is kept for the legacy stack. Since October 2016, the stack has been reduced to only include Smart Content Binding and JAX-RS Providers module in order to ease project maintenance.
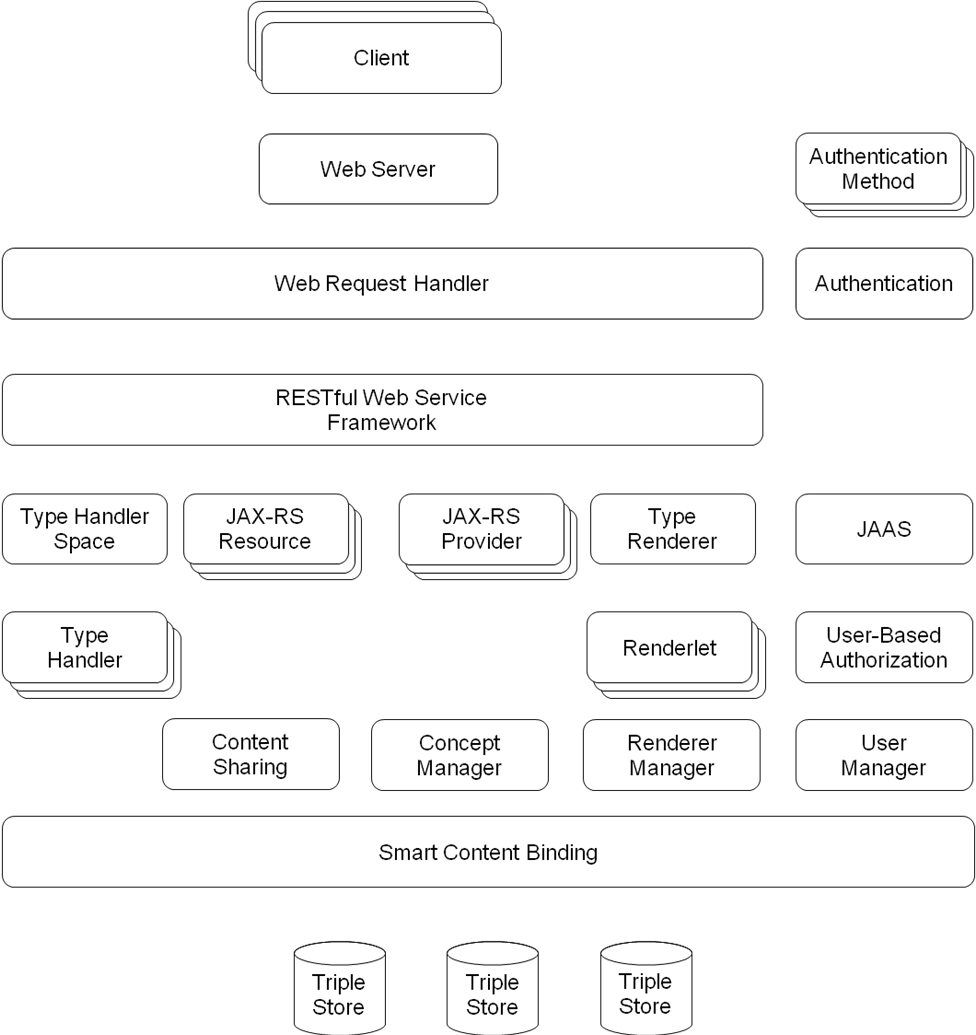
The OSGi (Open Services Gateway initiative) architecture is chosen as the underlying software architecture for the Apache Clerezza to achieve a service oriented and modular design of software components. The OSGi architecture is preferred compared to Service Component Architecture (SCA) · due to its maturity in implementation and support. Figure 1 presents the architectural components of Apache Clerezza. Interactions of those components are described in detail in subsequent sections. To perform a certain function, a component may use OSGi services provided by other components. OSGi services provided by a component can also be exposed as Web services, to be made accessible through the Web service framework.
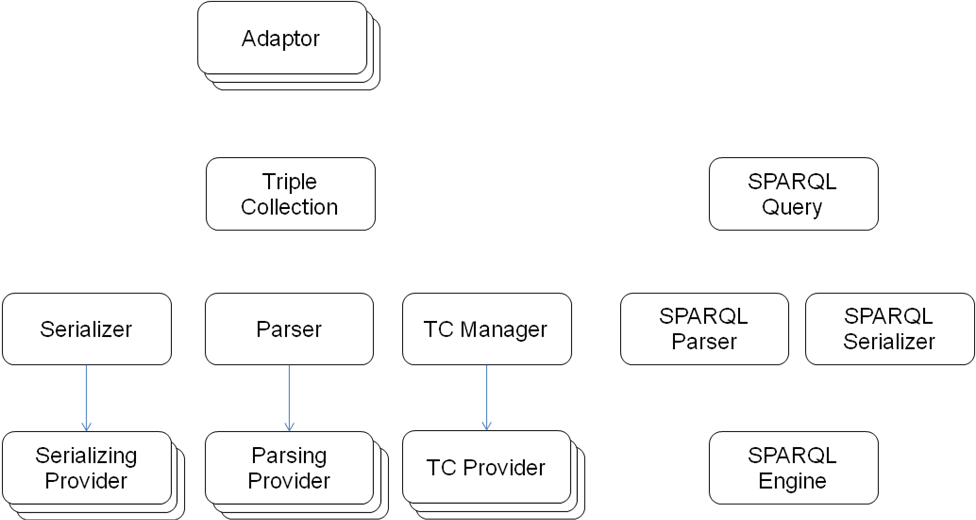
SCB defines a technology-agnostic layer to access and modify triple stores. It provides a java implementation of the graph data model specified by W3C RDF and functionalities to operate on that data model. SCB offers a service interface to access multiple named graphs and it can use various weighted providers to manage RDF graphs in a technology specific manner, e.g., using Jena · or Sesame. It also provides for adaptors that allow an application to use Jena or Sesame APIs to process RDF graphs. Furthermore, SCB offers a serialization and a parsing service to convert a graph into a certain representation (format) and vice versa. The architecture of SCB is depicted in Figure 2 and described in details in the following subsections.
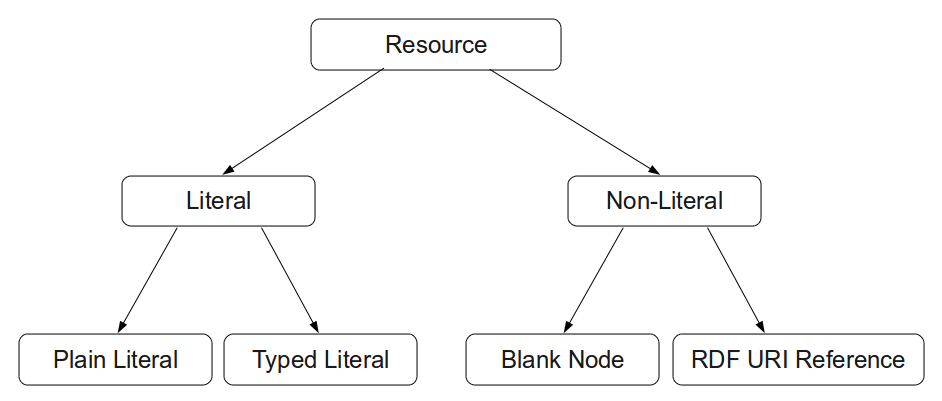
A Triple Collection is a set of triples, and thus, does not contain duplicates. A Triple Collection can be seen as a database in Relational Database Management Systems. Each triple comprises a subject, an object, and a predicate which relates the subject to the object. Note that, this relation is a directed relation. Possible data types (classes) that a subject, a predicate, or an object can have, is defined in Table 1. Figure 3 depicts the class diagram of those data types, which are described in detail in ·.
| Subject | Predicate | Object | |
|---|---|---|---|
| Plain Literal | - | - | x |
| Typed Literal | - | - | x |
| Blank Node | x | - | x |
| URI Reference | x | x | x |
The triples in a Triple Collection constitute a directed graph. Principally all triples can be placed within a single graph. However, it is practical to group triples and give them a name, resulting in a named graph. This name allows a graph to be referred to when accessing it. In many cases, it is useful to have graphs which are not modifiable, i.e., triples cannot be added to neither removed from the graph. Graphs which are not modifiable, are called Immutable Graphs (or just Graphs), whereas modifiable graphs are called Mutable Graph (or in short MGraph). Table 2 lists functions to be supported by MGraphs and Graphs.
| Function | Description | Triple Collection |
|---|---|---|
| Filter | Given a triple pattern, this operation must return all triples that match the pattern. | MGraphs and Graphs |
| Add Listener | Register a listener which will be notified if there is a change in the MGraph which match the specified pattern. | MGraphs |
| Remove Listener | Deregister a listener. | MGraphs |
| Equals | Test on isomorphism of two graphs. | Graphs |
In order to prevent concurrent modifications on an MGraph by different threads, a graph locking mechanism is required. Setting a read-lock on an MGraph prevents other threads from writing the MGraph, whereas setting a write-lock prevcnts other threads from reading and writing it.
A GraphNode is an object which represents a node (RDF resource) in a Triple Collection. It provides useful methods to obtain information about the node. Table 3 lists these methods and their descriptions.
| Function | Description |
|---|---|
| Get Node Context | The context of a node are the triples containing the node as subject or object and recursively the context of the blank nodes in any of these statements (triples). This method returns a Graph containing these triples. Blank nodes in this Graph are the same instances as in the original Triple Collection. |
| Delete Node Context | Delete the context of the node. |
| Get Objects | Get the objects of statements with this node as subject and a specified property as predicate. |
| Get Subjects | Get the subjects of statements with this node as object and a specified property as predicate. |
| Get Properties | Get all available properties of this node as subject. |
| Get Inverse Properties | Get all available properties of this node as object. |
| Add Property | Add a property to the node with the specified predicate and object. |
| Delete Properties | Delete all statement with the node as subject and the specified predicate. |
| Delete Property | Delete a statement with the node as subject, the specified property as predicate, and the specified resource as object. |
A Triple Collection (TC) Provider provides a service to access and manipulate Triple Collections implemented in a specific technology. Table 4 lists the main functions that a TC Provider must support.
| Function | Description |
|---|---|
| Create Graph | Create a Graph for the specified name with triples of the specified Triple Collection. |
| Create MGraph | Create an MGraph for the specified name. |
| Delete Triple Collection | Delete a Triple Collection, i.e. a Graph or MGraph of the specified name. |
| Get Graph | Return a Graph of the specified name. |
| Get MGraph | Return an MGraph of the specified name. |
A Parsing Provider provides the functionality to parse a Triple Collection from its serialized form into a Graph. Each Parsing Provider is characterized by its supported format. A Parser is a singleton that offers the parsing function by delegating it to registered Parsing Providers.
A Serializing Provider provides the functionality to serialize a Triple Collection into the specified format. Each Serializing Provider is characterized by its supported format. A Serializer is a singleton that offers the serialization function by delegating it to registered Serializing Providers.
SPARQL is a protocol and query language for RDF. The SCB architecture defines 4 components to support SPARQL: SPARQL Query, SPARQL Parser, SPARQL Serializer, and SPARQL Engine. In SPARQL Query, Java classes are defined to model the 4 forms of queries defined in SPARQL: Select, Construct, Ask, and Describe. The SPARQL Parser provides the functionality to parse a String into a Query object, whereas the SPARQL Serializer does the opposite. The SPARQL Engine provides a function to execute the specified SPARQL Query on the specified Triple Collection.
The Triple Collection (TC) Manager is a singleton that provides access to Triple Collections through registered TC Providers. It also provides methods to execute SPARQL queries through a registered SPARQL Query Engine.
The main component of the framework is an implementation of the JSR-311 (JAX-RS) specification ·, a Java API for RESTful Web services. The specification enables easy implementation of RESTful Web services using JAX-RS annotations, based on Java annotation mechanism. There are several implementations of this specification available, but trialox implementation called Triaxrs provided extended functionality, especially Type Handling and Type Rendering, which are described in detail in this section. Type Handling is a mechanism to select a Web service to process the Web request based on the RDF type of the requested resource, and Type Rendering is a mechanism to select a rendering definition to process the Web response based on the RDF type of the returned GraphNode.
A Web request is handled by a certain method of an intance of a certain Java class. This Java class is called a JAX-RS resource (in JAX-RS terminology, it is called a resource class), and the method is called a resource method. JAX-RS resources and their resource methods are annotated with JAX-RS annotations in order to allow Triaxrs to find and instantiate the right JAX-RS resource and invoke the right resource method to process an incoming Web request. JAX-RS annotations are used to specify URL paths, HTTP methods, consumed and produced media types, and Web request parameters.
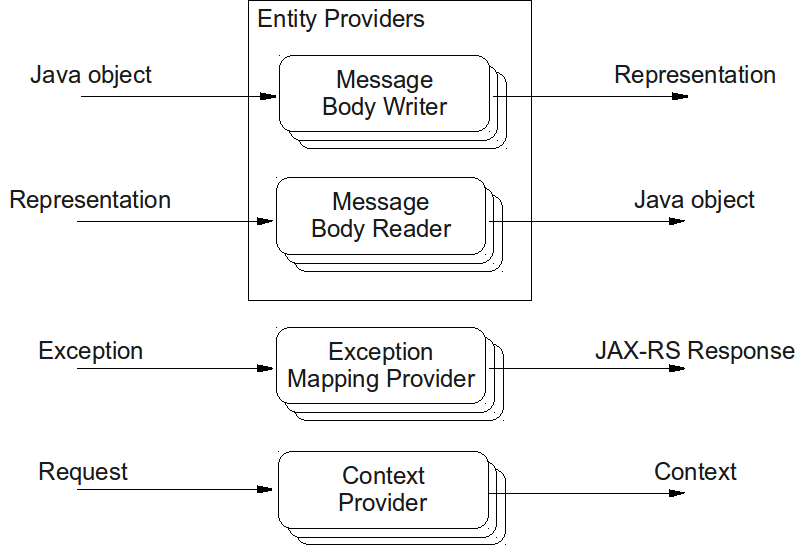
The functionality of a JAX-RS runtime is extended using application-supplied provider classes. JAX-RS specifies 3 types of providers: Entity Providers, Context Providers, and Exception Mapping Providers, as depicted in Figure 4. Entity providers supply mapping services between representations and their associated Java classes. There are 2 types of Entity Providers: Message Body Reader (MBR) and Message Body Writer (MBW). Context Providers supply context to resource classes and other providers, while Exception Mapping Providers map a checked or runtime exception to an instance of JAX-RS Response. Interested readers are recommended to study · for detail descriptions of JAX-RS providers and applicable JAX-RS annotations.
A number of MBRs and MBWs are to be implemented within the framework in order to support Java classes which are often used. They are listed in Table 5.
| Java Class | MBR | MBW |
|---|---|---|
| String | x | x |
| byte[] | x | x |
| java.io.File | x | x |
| javax.ws.rs.core.MultivaluedMap |
x | x |
| java.io.InputStream | x | x |
| java.io.Reader | x | x |
| javax.xml.transform.stream.StreamSource | x | - |
| javax.xml.transform.sax.SAXSource | x | - |
| javax.xml.transform.dom.DOMSource | x | - |
| javax.xml.transform.Source | - | x |
| javax.ws.rs.core.StreamingOutput | - | x |
| org.apache.clerezza.jaxrs.utils.form.MultiPartBody (defined by apache clerezza for HTML form's content type multipart/form-data | x | - |
| org.apache.clerezza.rdf.core.Graph (implemented within SCB) | x | x |

Figure 5 shows the typical sequence of interactions between various components involved in the processing of a Web request after delivered to the Triaxrs Core. The Triaxrs Core selects a resource method by matching annotated resource methods to the Web request. Before invoking the matched method, all parameters of the method are constructed by using relevant Context Providers and Message Body Readers. The result of the method invocation is a Java object (an instance of a certain Java class). The Triaxrs Core looks for a matching MBW to render the resulting Java object. Finally, a Web response is generated and sent to the requesting client through the Web server.
In JAX-RS specification, the URL of a Web request determines candidate JAX-RS resources and methods, whereas RDF uses a URI Reference (which can also be used as URL) to identify a resource. Note that an RDF resource can also be a blank node, in which case it is not processable through Type Handling. Therefore, a Type Handler Space can be annotated to match any URL, and it can use the URL as the URI Reference of the RDF resource to be processed. However, this requires:

The sequence of a Web request processing involving a Type Handler is depicted in Figure 6. The Type Handler Space matches any URL and returns a Type Handler supporting an RDF type of the RDF resource requested. In order to find the right Type Handler, the Type Handler Space needs to access the Triple Store which has the triple stating the RDF type of the requested RDF resource. Furthermore, Type Handlers are annotated with information on supported RDF types and a property denoting that the Java class is a Type Handler. The Type Handler acts as a JAX-RS sub-resource to be matched with the HTTP method of the Web request. The matching sub-resource method is then invoked with the required parameters by the Triaxrs Core. The remaining steps are the same as in the previous Section.
Similar to Type Handling a mechanism to map the RDF type of an RDF resource to a rendering definition will be useful. This mechanism is termed Type Rendering. A rendering definition stores the following information:
In order to support Type Rendering in Triaxrs, a generic Message Body Writer for GraphNodes is required, which is annotated as being capable to produce any media type. Based on the accept header of the Web request, the optional query parameter “mode” in the Web request, and the RDF type of the GraphNode to be rendered, a matching rendering definition is selected. The renderlet is extracted from the rendering definition and its render method is invoked to render the GraphNode according to the rendering specification.

Some services provided by Apache Clerezza are restricted to specific users only. Therefore, Apache Clerezza must support user authentication and authorization.
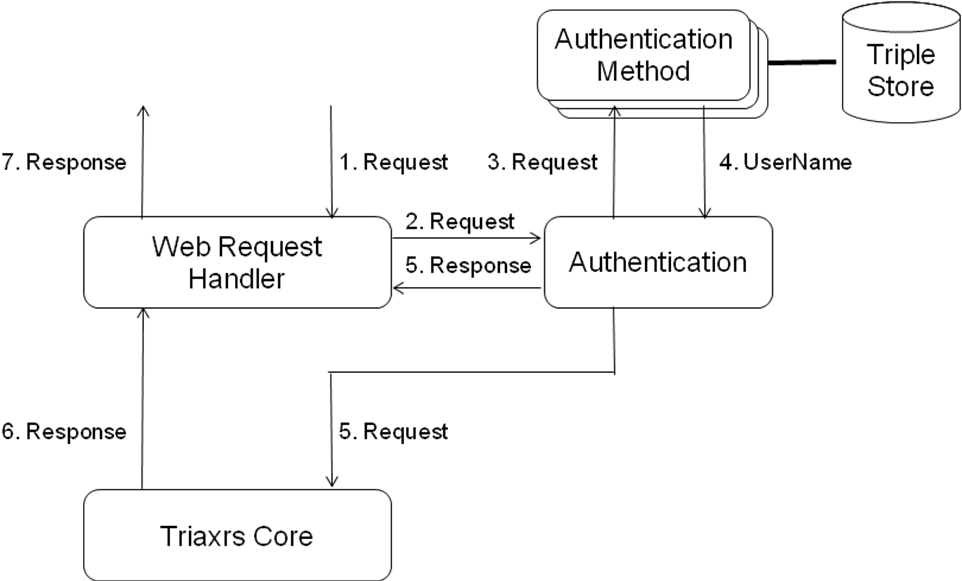
Figure 8 shows the authentication process. Before a Web request is delivered to Triaxrs Core for processing, the user who submitted the Web request must first be authenticated. The Web Request Handler forwards the Web request received from the Web server to the Authentication component. This component invokes registered Authentication Methods in a sequence according to their priority (weight). Each Authentication Method extracts user credentials from the Web request and returns the user name if the user can be authenticated successfully. Otherwise, it generates a Web response to inform the client about the failed authentication. The platform should support HTTP basic authentication and cookie-based authentication. In case of HTTP basic authentication, if the Web request does not contain the user credentials, the UNAUTHORIZED response status code is sent to the client. In case of cookie-based authentication, a failed authentication leads to a redirection to a login page.
After the user (a.k.a subject in JAAS) is successfully authenticated, the Web request is delivered to the Triaxrs Core to be processed. This Web request processing is carried out within the method Subject.doAsPrivileged, a JAAS authorization mechanism. This method receives three parameters: a subject, an action, and an access control context. The specified action is carried out as the specified subject within the specified access control context. This means, Triaxrs Core processes the Web request on behalf of the authenticated user (subject). Doing this is necessary to enable checking the rights of a subject to perform a particular action, as described in the next section.
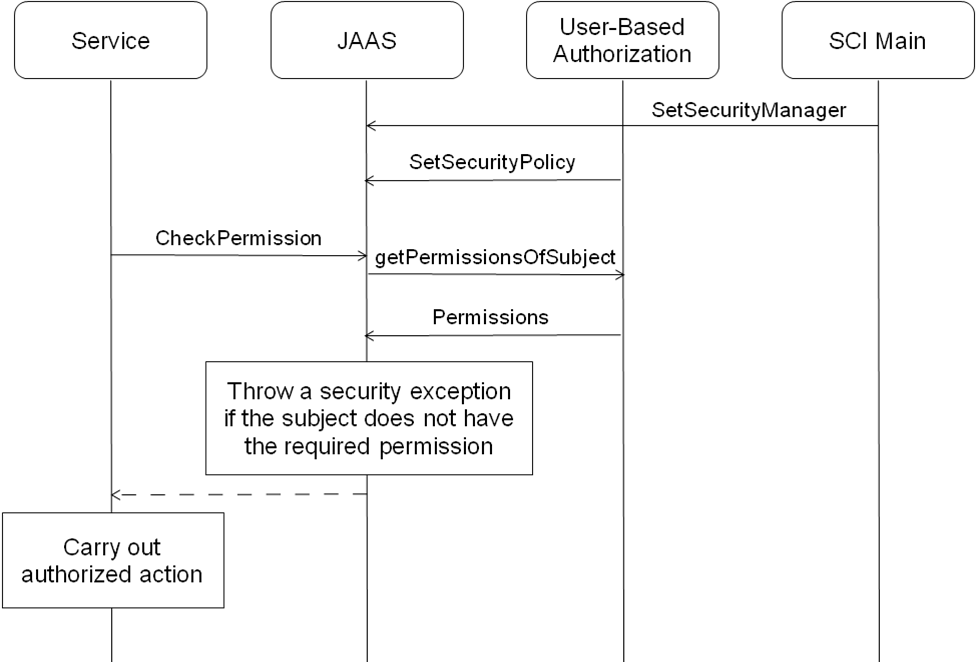
Authorization in Apache Clerezza is based on JAAS. The following steps are performed to use JAAS for authorization:
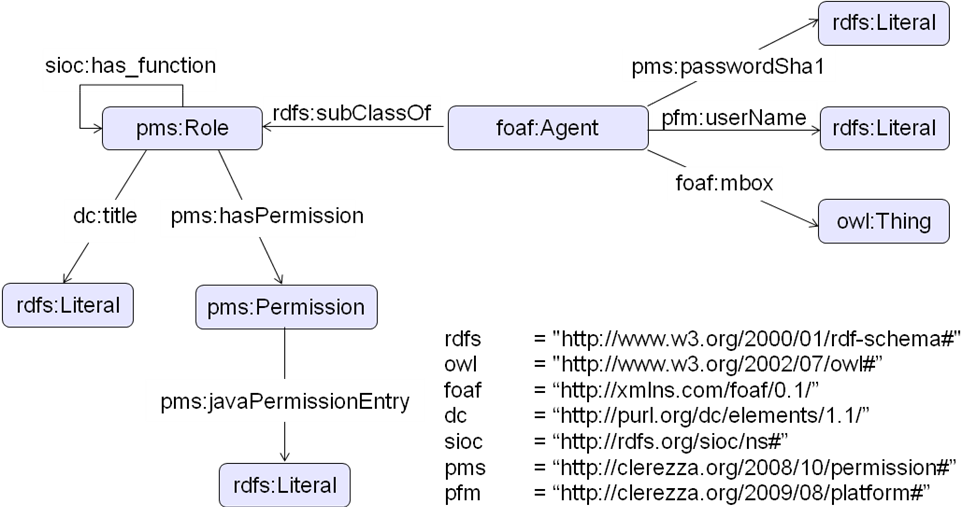
The User Manager provides a service to create users and roles, and assign permissions to them. A role represents a set of rights which are needed by a user having a certain function to perform her tasks. To describe users and roles, a set of ontologies is used as depicted in Figure 10. A user is defined as a FOAF Agent, and she can be assigned a set of roles. A user inherits the permissions of her roles. This means, assigning a user a certain role has the effect of assigning the permissions of this role to the user. Furthermore, a user can be assigned role-independent permissions. The property has_function of SIOC is used to assign roles to users. By applying this property also to roles, all permissions of a role can be passed on to other roles. Since properties of the class Role are also properties of the class Agent, the class Role is defined as a superclass of the class Agent.
Two own ontology namespaces are defined, as can be seen in Figure 10: PLATFORM and PERMISSION. This is due to the fact, that existing ontologies do not provide required properties and classes. Instead of FOAF name, the property userName, defined in own ontology termed PLATFORM, is used to identify a user, because unlike FOAF name, the value of userName must be unique. To allow usage of permission definitions besides Java-based permissions, the class Permission in the namespace PERMISSION is specified. Therefore, the property hasPermission points to an object of the class Permission.
Apache Clerezza pre-defines two roles: base-role and default-role. The base-role has a set of permissions which allow a user having this role to use services made public by Apache Clerezza. This requires read access to various graphs and the following Java permission specification: (java.util.PropertyPermission "*" "read") and (org.osgi.framework.AdminPermission "*" "resource"). Any user implicitly has the base-role. A user with a default-role has additionally the permissions to change her password and access her account control panel to view or modify her account data. Besides roles, Apache Clerezza also pre-defines two users: anonymous and admin. The user anonymous has only the base-role, whereas the user admin has all permissions.

